情報技術科 No.3 氏家 彬
①研究の背景
普段皆さんは容量の大きな文字データを誰かに送るときどうしているでしょうか?
皆さん何かしらの圧縮ソフトを用いて圧縮してから送信していたりすると思います。
ですが皆さんその圧縮過程はあまり知らないかなと思います
私はその圧縮過程を知ることで知識を深めることができると考えたので
文字ファイルの圧縮の研究に取り組みました。
②仮説とねらい
上記のように文字ファイルの圧縮を研究しますがファイルの圧縮として
代表的なのはLhaplusなどの圧縮ソフトなどだと思います。

ただ一言で圧縮ソフトといっても様々な方法があります。
なので今回の研究では自分なりの圧縮方法を考えることでより理解が深まると思います。
③研究内容
研究内容としては様々な圧縮方法を学び、そのうえでどんな圧縮方式を使用するか決めプログラムを作成、そしてプログラムを使用して様々なテキストファイルを圧縮し、その結果を比較します。
④技術的知識
今回圧縮プログラムを考えていく上でプログラミング言語を使い制作していくことになりますが使用言語としてはC言語を使用することにしました
研究内容で書かれた単語の解説
- 可逆圧縮
圧縮したファイルを解凍した時にデータがもとに戻る圧縮法 - ハフマン法 LZ77符号化 連長符号化など
可逆圧縮の中の一つの圧縮法
⑤取り組んだ内容
- 圧縮方式の決定
・同じ記号が多く出るものに向いている
・圧縮過程がわかりやすい
などの理由からハフマン符号化を実装すると決定 - 圧縮プログラムの作成
プログラムの流れ
・各文字の出現率をカウント
・各文字の出現率を元にハフマン木を生成
・各文字の符号を算出
・データの符号化 - 様々なテキストファイルを圧縮
・英語ファイルの圧縮
・日本語ファイル
⑥結果
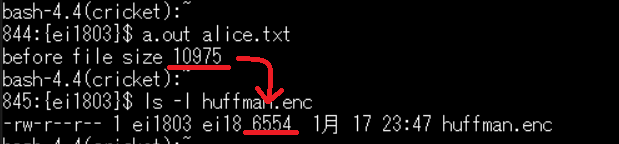
- 英語ファイルの圧縮
10975バイト→6554バイト 圧縮成功
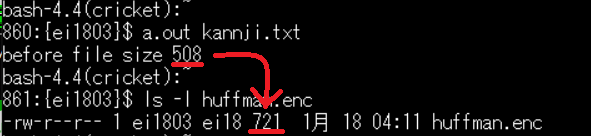
2.日本語ファイルの圧縮
508バイト→721バイト サイズ増加
- 何故か
日本語ファイル…文字の種類が多く頻出率に差がない
↓
逆に一文字に割り当てられるビット数が増えてしまうのではないか
でも…
英語ファイル、日本語ファイル→UTF-8で書かれている
↓
日本語も圧縮できるはず - 別の原因
日本語ファイルは英語ファイルと比べてデータサイズが小さい
↓
文章量が少ないから頻出率に差がないのでは - 検証
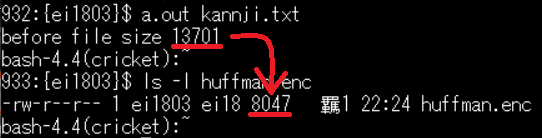
508バイト→13701バイトにサイズ変更しもう一度実行
13701バイト→ 8047バイト 圧縮成功
⑦感想・考察
今回の課題研究を通して私は様々な圧縮方法について学ぶことができたと感じた
特に今回使用したハフマン符号化はしくみを学ぶだけでなくプログラムを自分で作成したことで、一つひとつの過程を自分なりに考えたため、ハフマン符号化について少なからず理解することができたのではないかと感じた。
また、今回の課題研究ではできなかったが英語と日本語での違いだけでなく、同じ内容にしたテキストファイルで、文字コードによってどれだけ圧縮率が違うかなどについてもできたのではないかと感じた。